
随着大型语言模型(LLM)技术的日渐成熟,其应用范围正在不断扩大。从智能写作到搜索引擎,LLM 的应用潜力正在一点点被挖掘。
最近,微软亚洲研究院提出可以将 LLM 用于工业控制,而且仅需少量示例样本就能达成优于传统强化学习方法的效果。该研究尝试使用 GPT-4 来控制空气调节系统(HVAC),得到了相当积极的结果。

论文地址:http://export.arxiv.org/abs/2308.03028
在智能控制领域,强化学习(RL)是最流行的决策方法之一,但却存在样本低效问题以及由此导致的训练成本高问题。当智能体从头开始学习一个任务时。传统的强化学习范式从根本上讲就难以解决这些问题。毕竟就算是人类,通常也需要数千小时的学习才能成为领域专家,这大概对应于数百万次交互。
但是,对于工业场景的许多控制任务,比如库存管理、量化交易和 HVAC 控制,人们更倾向于使用高性能控制器来低成本地处理不同任务,这对传统控制方法而言是巨大的挑战。
举个例子,我们可能希望只需极少量的微调和有限数量的参考演示就能控制不同建筑的 HVAC。HVAC 控制可能在不同任务上的基本原理都类似,但是场景迁移的动态情况甚至状态 / 动作空间可能会不一样。
不仅如此,用于从头开始训练强化学习智能体的演示通常也不够多。因此,我们很难使用强化学习或其它传统控制方法训练出普遍适用于这类场景的智能体。
使用基础模型的先验知识是一种颇具潜力的方法。这些基础模型使用了互联网规模的多样化数据集进行预训练,因此可作为丰富先验知识的来源而被用于各种工业控制任务。基础模型已经展现出了强大的涌现能力以及对多种下游任务的快速适应能力,具体的案例包括 GPT-4、Bard、DALL-E、CLIP。其中前两者是大型语言模型(LLM)的代表,后两者则能处理文本和图像。
基础模型近来取得的巨大成功已经催生出了一些利用 LLM 执行决策的方法。这些方法大致上可分为三类:针对具体下游任务对 LLM 进行微调、将 LLM 与可训练组件组合使用、直接使用预训练的 LLM。
之前的研究在使用基础模型进行控制实验时,通常选用的任务是机器人操控、家庭助理或游戏环境,而微软亚洲研究院的这个团队则专注于工业控制任务。对传统强化学习方法而言,该任务有三大难点:
1) 决策智能体通常面对的是一系列异构的任务,比如具有不同的状态和动作空间或迁移动态情况。强化学习方法需要为异构的任务训练不同的模型,这样做的成本很高。
2) 决策智能体的开发过程需要很低的技术债(technical debt),这说明所提供的样本数量不够(甚至可能没有),而传统的强化学习算法需要大数据才能训练,因此可能无法设计针对特定任务的模型。
3) 决策智能体需要以在线方式快速适应新场景或不断变化的动态情况,比如完全依靠新的在线交互经验而无需训练。
为了解决这些难题,微软亚洲研究院的 Lei Song 等研究者提出直接使用预训练 LLM 来控制 HVAC。该方法只需少量样本就能解决异构的任务,其过程不涉及到任何训练,仅使用样本作为少样本学习的示例来进行上下文学习。
据介绍,这项研究的目标是探索直接使用预训练 LLM 来执行工业控制任务的潜力。具体来说,他们设计了一种机制来从专家演示和历史交互挑选示例,还设计了一种可将目标、指示、演示和当前状态转换为 prompt 的 prompt 生成器。然后,再使用生成的 prompt,通过 LLM 来给出控制。
研究者表示,其目的是探究不同的设计方式会如何影响 LLM 在工业控制任务上的表现,而该方法的很多方面都难以把控。
- 第一,尽管该方法的概念很简单,但相比于传统的决策方法,其性能表现还不明朗。
- 第二,基础模型向不同任务的泛化能力(比如对于不同的上下文、动作空间等)仍然有待研究。
- 第三,该方法对语言包装器不同设计的敏感性也值得研究(例如,prompt 中哪一部分对性能影响最大)。
研究者希望通过解答这些问题凸显出这些方法的潜力以及展现可以如何为技术债较低的工业控制任务设计解决方法。
这篇论文的主要贡献包括:
- 开发了一种可将基础模型用于工业控制但无需训练的方法,其能以较低的技术债用于多种异构的任务。
- 研究者通过 GPT-4 控制 HVAC 进行了实验,得到了积极的实验结果,展现了这些方法的潜力。
- 研究者进行了广泛的消融研究(涉及泛化能力、示例选取和 prompt 设计),阐明了该方向的未来发展。
方法
该研究使用 GPT-4 来优化对 HVAC 设备的控制,工作流程如下图 1 所示:
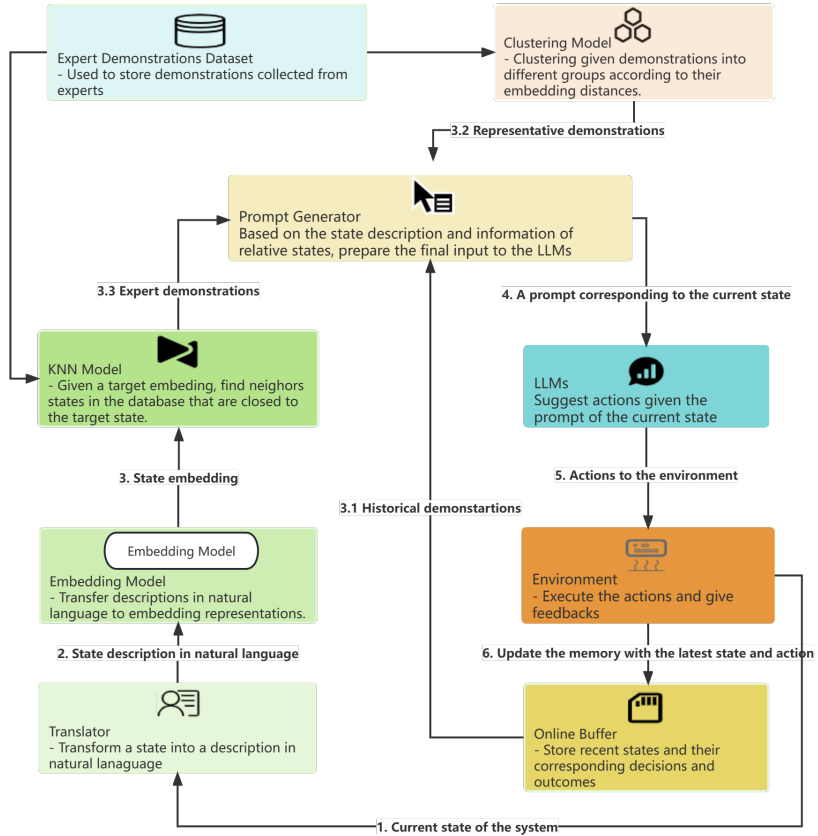
图 1:使用 GPT-4 控制 HVAC 的工作流程示意图
该工作流程中的 LLM 和环境组件如下:
LLM:一个预训练大型语言模型,用作决策器。它会根据给出的 prompt 生成对应的响应。其 prompt 中应包含对当前状态的描述、简单的 HVAC 控制指令、相关状态的演示等。
环境:一个交互式环境或模拟器,可以执行 LLM 建议的动作并提供反馈。实验中所使用的具体评估环境为 BEAR (Zhang et al., 2022a)。为了在 BEAR 中创建环境,必须提供两个参数:建筑类型(如大型办公室、小型办公室、医院等)和天气条件(如炎热干燥、炎热潮湿、温暖干燥等)。此外,值得注意的是,每种天气状况都对应于特定的城市。例如,炎热干燥的天气状况与水牛城有关。
在 BEAR 中,每个状态都由一个数值向量表示,其中除了最后四个维度外,每个维度都对应于建筑物中一个房间的当前温度。最后四个维度分别代表室外温度、全局水平辐射(GHI)、地面温度和居住者功率。在所有环境中,首要目标是保持室温在 22 ℃ 附近,同时尽可能减少能耗。
BEAR 中的操作被编码为范围从 -1 到 1 的实数。负值表示制冷模式,正值表示加热模式。这些动作的绝对值对应于阀门打开程度,这能说明能耗情况。如果绝对值更大,那么能耗也就更大。在兼顾舒适度和能耗的条件下,研究者在实验中使用了以下奖励函数:
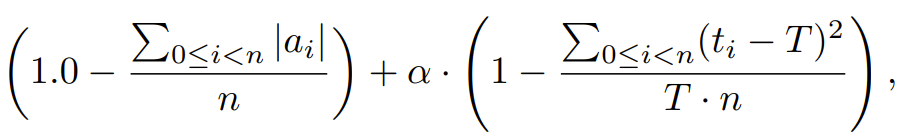
其中 n 表示房间数,T=22℃ 是目标温度,t_i 表示第 i 个房间的温度。超参数 α 用于实现能耗和舒适度的平衡。
此外,该工作流程中还包含在线缓冲器、转译器、嵌入模型、专家演示数据集、KNN 模型、聚类模型、prompt 生成器等组件。其中 prompt 生成器的执行过程如图 2 所示,其中紫色的文本仅用于说明,而非 prompt 的一部分。
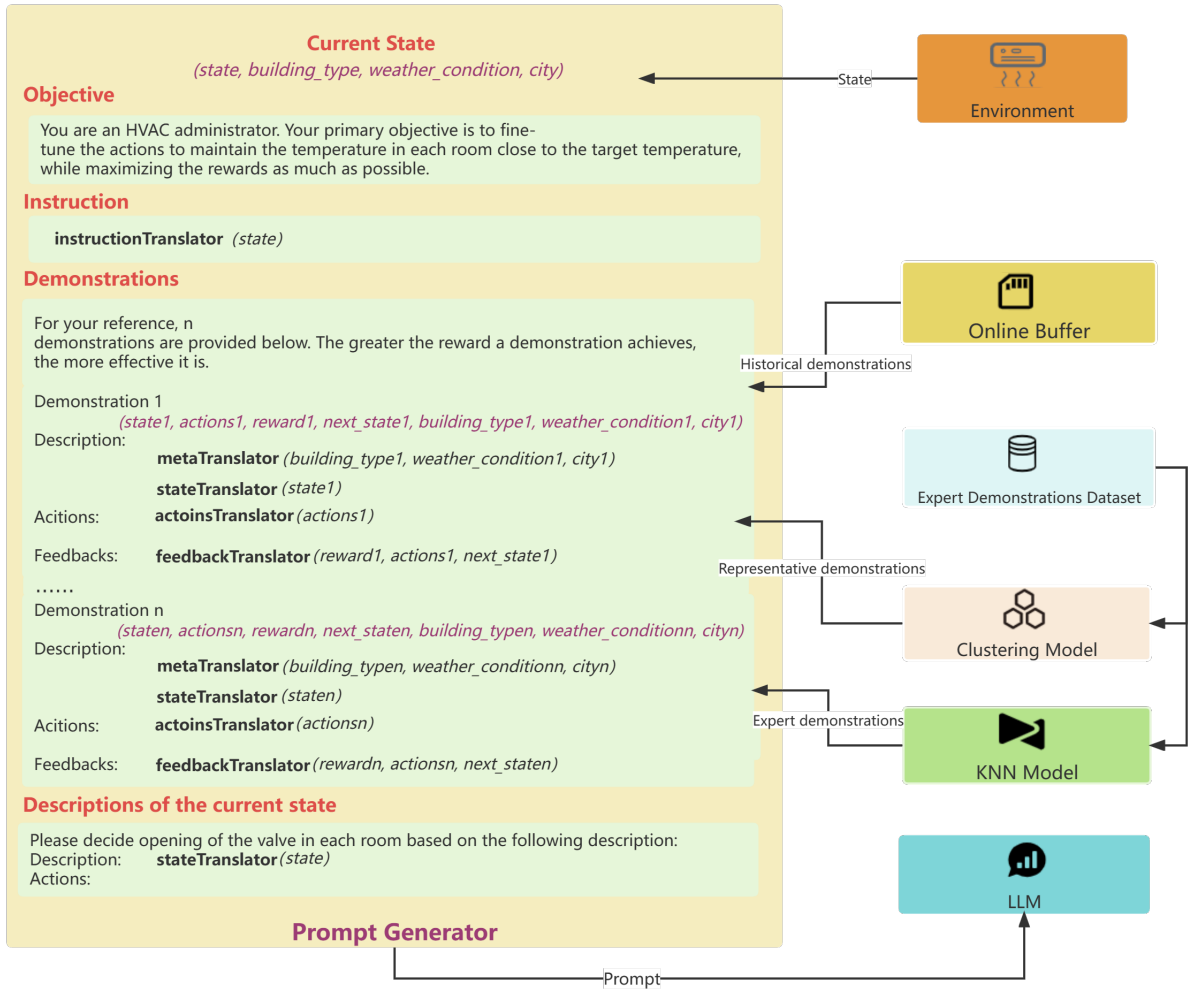
图 2:新方法是如何生成 prompt 的
实验
该研究通过实验展示了 GPT-4 控制 HVAC 设备的效果,其中涉及不同的建筑物和天气条件。只要能提供适当的指示和演示(不一定与目标建筑和天气条件相关),GPT-4 的表现就能超过专门为特定建筑和天气条件精心训练的强化学习策略。此外,研究者还进行了全面的消融研究,以确定 prompt 中每个部分的贡献。
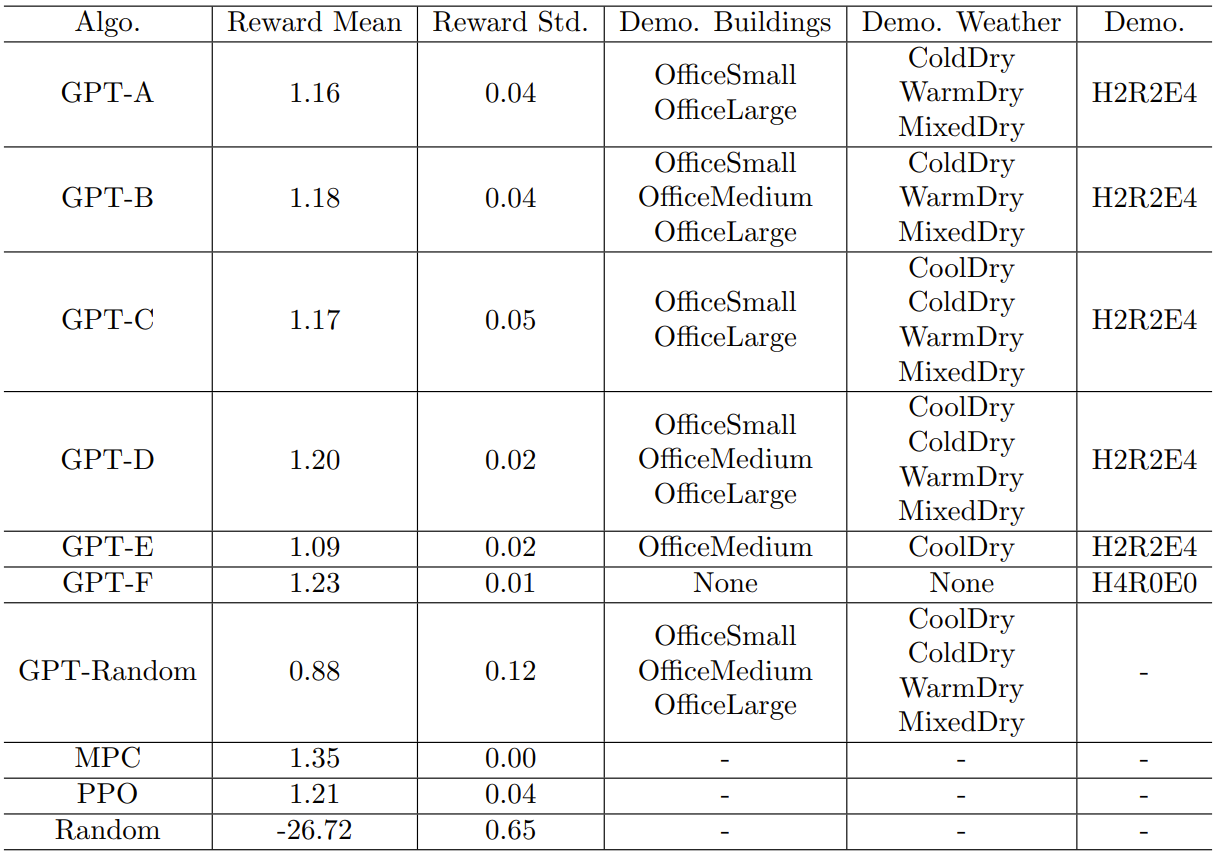
表 1:GPT-4 使用不同专家演示时的表现
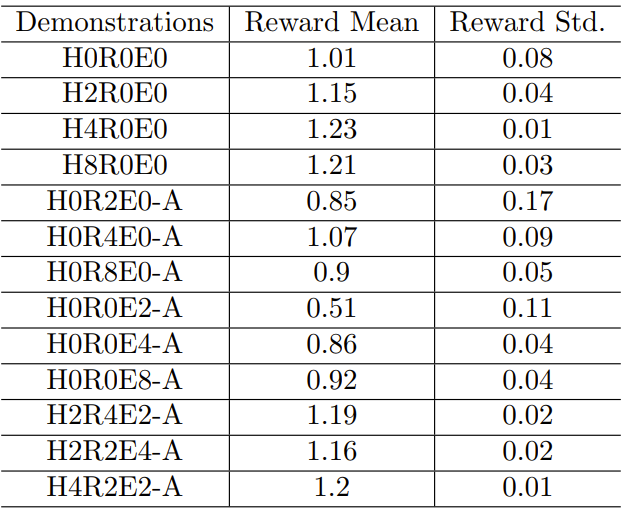
表 2:GPT-4 使用不同类型和数量的演示时的表现
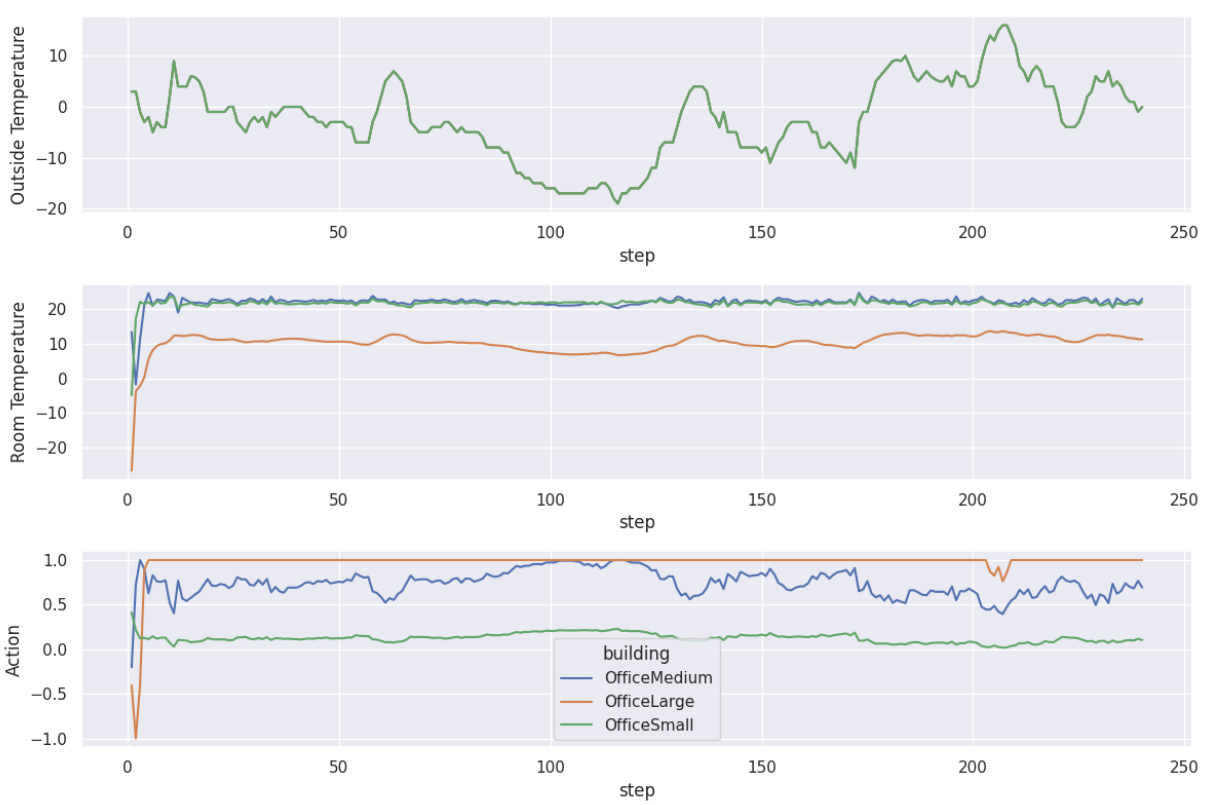
图 3:在相同天气条件下,不同建筑对应不同的专家策略的情况
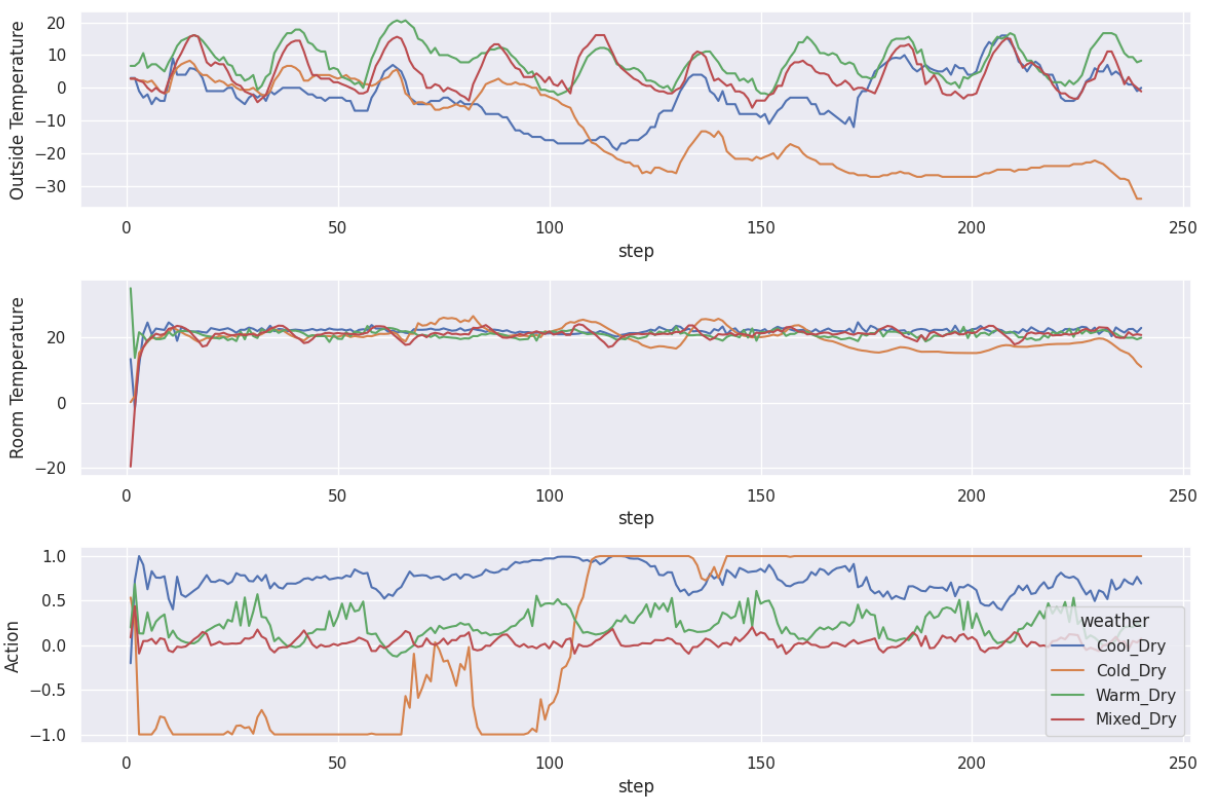
图 4:在不同天气条件下,同一建筑使用不同专家策略的情况
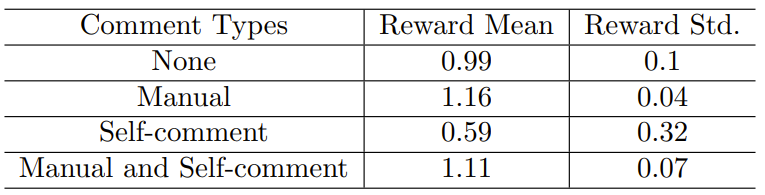
表 3:GPT-4 使用不同类型的注释时的表现
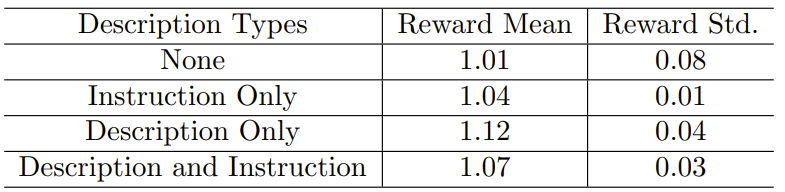
表 4:GPT-4 使用不同类型的描述和指示时的表现

表 5:在 prompt 中实数是否进行舍入的不同情况下,GPT-4 的性能
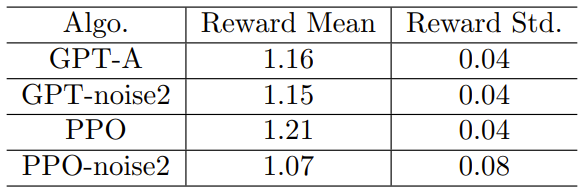
表 6:PPO 和 GPT 在天气扰动下的表现

